|
An internet browser by Stanza. V1. 2001- 2002
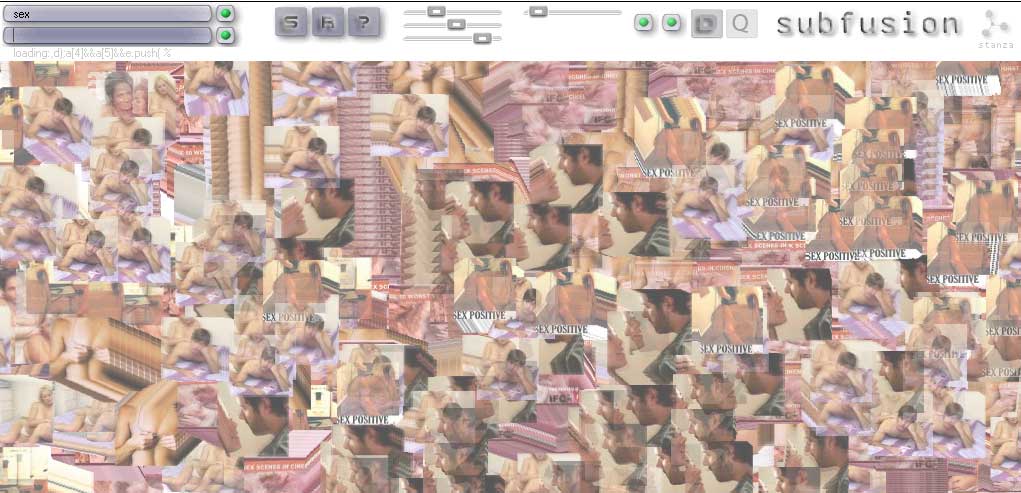
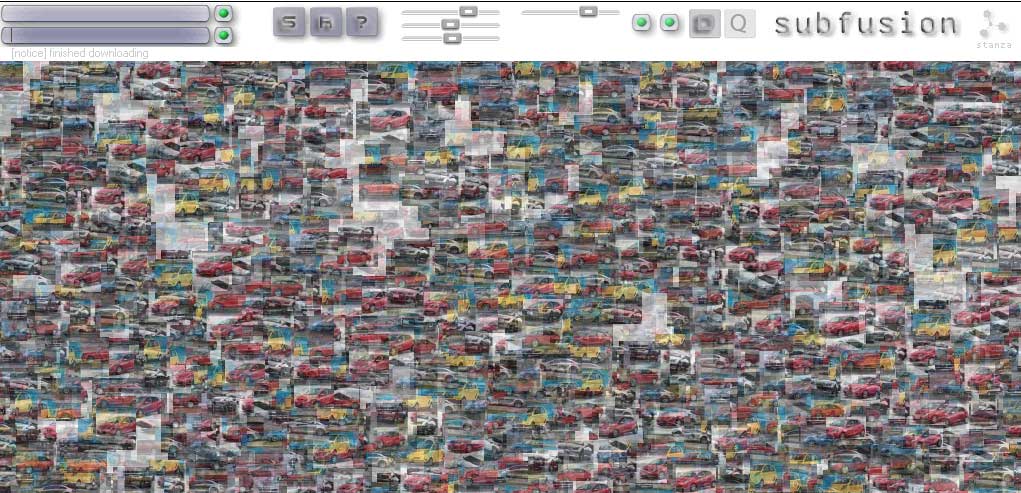
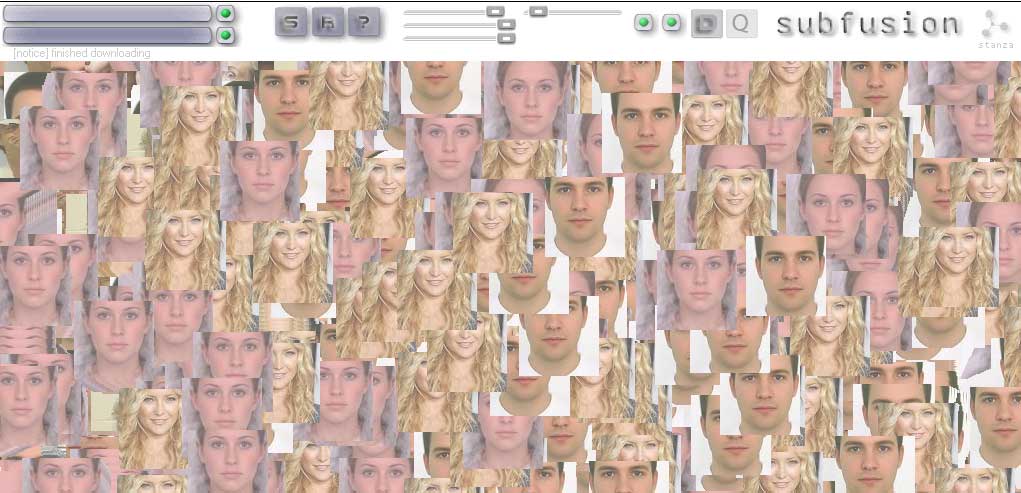
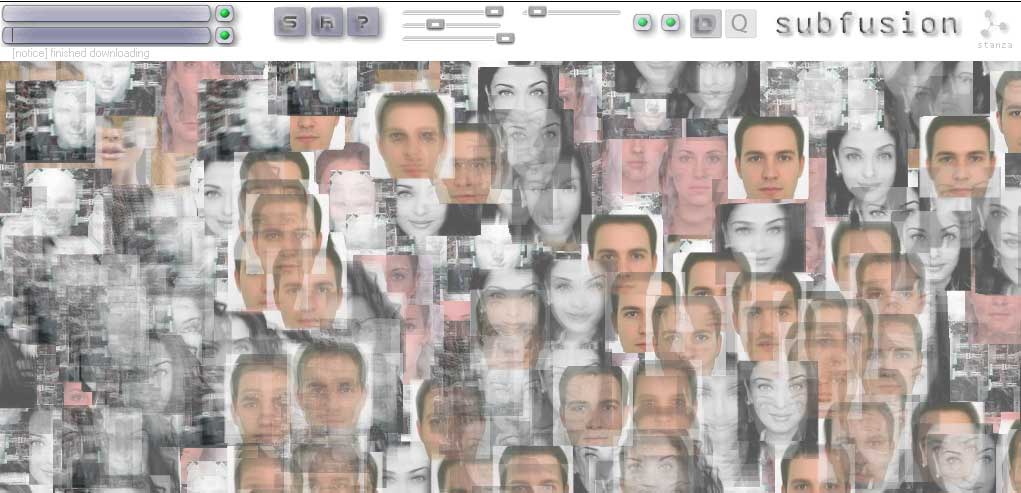
Subfusion makes collages, cut out from the sections of the web, where sounds and images appear relevant to your search. This software fuses sound and images, constantly making collages and chopping them up again.It has a fully integrated generative audio visual system built into it. The sounds are generative, spliced, chopped and looped. Subfusion is the abstracted noise based visual destruction of the browser, the desktop, and the interface. You enter words and the software brings back images and sounds and mashes them up as a collage a media visualisation. This browser acts like a audio visual thesaurus. The top search field looks for images. Type in words and pictures appear. Use the slider to control various aspects of the images, ie their size or movement and speed. The lower search field looks for sounds online, and the switched make these sounds mix together. Available for exhibitions and prints are available as signed original artworks. Exhited at ZKM as part of the exhibition CHOSE YOUR FILTER 2025. Curators: Inge Hinterwaldner (KIT), Daniela Hönigsberg (KIT), Laura C. Schmidt (ZKM) Subfusion is highly relevant to the techniques of AI and Large Language Models (LLMs) because it anticipates many of the core principles that define generative systems today. Although it predates contemporary large-scale generative AI by twenty years, it operates through computational processes that closely resemble how AI models retrieve, synthesize, and recombine data. Subfusion is significant because it anticipates the logic of AI and LLMs before their widespread adoption. By turning search queries into generative audiovisual collages, it demonstrates early experimentation with algorithmic creativity, multimodal data fusion, and interactive parameter control. Rather than simply retrieving information, Subfusion transforms it — much like generative AI systems today. In this sense, it can be understood as a technological and conceptual forerunner to contemporary AI-driven generative art and language models.Subfusion pulls images and sounds from the web based on user-entered words. This mirrors how AI systems rely on vast datasets scraped or collected from the internet. Large Language Models generate outputs by predicting and recombining patterns from training data. They do not invent from nothing; they synthesize. Subfusion functions similarly. It does not create entirely new images or sounds from scratch — instead, it remediates, splices, loops, and fuses existing media into new configurations. Subfusion’s constant chopping, layering, and restructuring of content parallels the probabilistic assembly process used in generative AI.Subfusion acts as an early interface for parameter-driven generation, anticipating the human–AI feedback loop now central to LLM and image-generation systems. Subfusion reimagines the browser as an algorithmic generator rather than a navigation tool. In this way, it prefigures how AI reshapes our interaction with information. Although it does not use neural networks in the modern sense, its conceptual structure mirrors AI logic: input → retrieval → recombination → output. Screenshots
Keywords: Net art, mash up, generative, software, networked, interactive, audio visual, software, artwork Credits. An artwork by Stanza [Steve Tanza]. Thanks to all those who I have asked for technical advice on this project. Thanks most to 'atom oil' for gluing it together. |